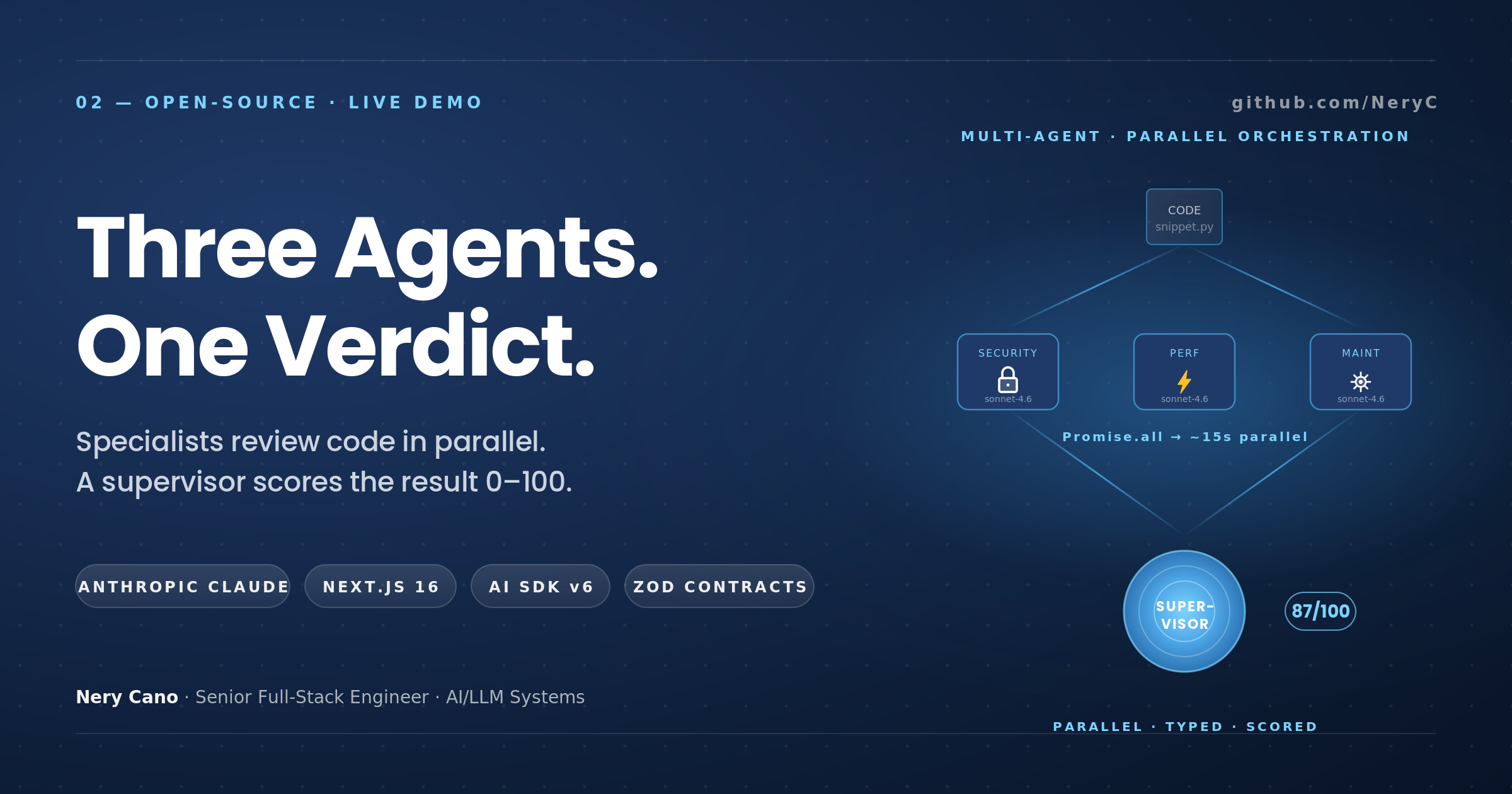
How Promise.all, Zod, and Server-Sent Events compose into a multi-agent system that's easier to reason about than a single big LLM.
A single LLM doing "general code review" is mid.
Not because LLMs are bad — they're great. But ask one model to find security bugs, performance bugs, and maintainability bugs all at once, and you'll see the same failure modes show up over and over: it skews toward whatever category looks most obvious in the snippet, drops findings when the code gets long, and produces unbalanced reports — five style nits, zero security flags, on a SQL injection that's plain as day.
I built a code reviewer that doesn't have that problem. The trick was to stop asking a single agent to be a generalist and instead orchestrate three specialists in parallel with a supervisor consolidating their findings.
This post walks through the architecture, the three engineering decisions I'd defend in any review, and the small but important surprises that came up while building it.
🔗 github.com/NeryC/multi-agent-code-reviewer · live demo
The architecture in one diagram
┌──────────────┐
code ──► │ parseInput │ (snippet or GitHub URL)
└──────┬───────┘
▼
┌──────────────┐
│ extractMeta │ (lang, lines, complexity)
└──────┬───────┘
▼
┌─────────── Promise.all ───────────┐
│ │
▼ ▼ ▼
┌───────┐ ┌────────┐ ┌──────────┐
│ Sec │ │ Perf │ │ Maint │
│ agent │ │ agent │ │ agent │
└───┬───┘ └───┬────┘ └────┬─────┘
└──────────────┼──────────────────┘
▼
┌──────────────┐
│ Supervisor │ (deduplicates, scores 0–100, summary)
└──────┬───────┘
▼
report
All four agents are LLM calls. The three specialists are claude-sonnet-4.6. The supervisor is claude-haiku-4.5 (cheaper, fine for the mechanical sort/dedupe job). Every step is streamed back to the browser as Server-Sent Events so the user sees a live timeline of what's happening, not a 30-second loading spinner.
Decision 1 — Promise.all, not sequential
The naive way to run three agents is to await them one after another:
const sec = await runSecurityAgent(code, meta);
const perf = await runPerformanceAgent(code, meta);
const maint = await runMaintainabilityAgent(code, meta);
That works, but it's 3× slower than it has to be. Each agent makes an independent LLM call; none of them needs the others' output. A 15-second per-agent latency adds up to ~45 seconds of "loading…"
Promise.all parallelizes the three calls trivially:
const [secFindings, perfFindings, maintFindings] = await Promise.all([
runSecurityAgent(code, meta).then((findings) => {
send({ type: 'agent', name: 'security', status: 'done', findings });
return findings;
}),
runPerformanceAgent(code, meta).then((findings) => {
send({ type: 'agent', name: 'performance', status: 'done', findings });
return findings;
}),
runMaintainabilityAgent(code, meta).then((findings) => {
send({ type: 'agent', name: 'maintainability', status: 'done', findings });
return findings;
}),
]);
// Supervisor needs all three — runs after.
const report = await runSupervisorAgent(
[...secFindings, ...perfFindings, ...maintFindings],
meta,
);
Three things to notice:
- Total latency is now
max(t_sec, t_perf, t_maint)≈ 15s, not their sum. - The
.then(...)chains let me send an SSE event the moment each agent finishes, in whatever order they happen to finish. The UI shows "✓ Maintainability done · 🔄 Security still running" without me having to plumb anything special. - The supervisor naturally runs after
Promise.allresolves — no extra awaits needed; the data dependency is enforced by the call site.
If your agents do depend on each other (e.g. agent B needs agent A's output to plan its query), Promise.all won't help and you should keep the sequential pattern. But for code review, where each specialist has a different lens on the same input, parallel is free latency.
Decision 2 — Zod schemas as agent contracts
This is the single most important pattern I've adopted in 2026 for working with LLMs.
The old way: ask the model nicely to return JSON, then JSON.parse() and hope nothing weird happens. This fails in three ways:
- The model returns
```json ... ```markdown-fenced output and your parser breaks. - The model invents a field that doesn't exist in your TypeScript type.
- The model omits a required field; you don't notice until production.
The new way: pass a Zod schema to AI SDK v6's generateObject, and let the SDK enforce the shape on the way out of the model.
const FindingSchema = z.object({
severity: z.enum(['critical', 'high', 'medium', 'low', 'info']),
category: z.enum(['security', 'performance', 'maintainability']),
title: z.string(),
line: z.number().int().positive().optional(),
description: z.string(),
suggestion: z.string(),
codeExample: z.object({
before: z.string(),
after: z.string(),
}).optional(),
});
const FindingArraySchema = z.array(FindingSchema);
export async function runSecurityAgent(code: string, meta: CodeMetadata): Promise<Finding[]> {
const { object } = await generateObject({
model: REVIEW_MODEL, // claude-sonnet-4.6
schema: FindingArraySchema, // ← the contract
system: SYSTEM_PROMPT_SECURITY,
prompt: `Language: ${meta.lang}\nLines: ${meta.lines}\n\nCode:\n\`\`\`${meta.lang}\n${code}\n\`\`\``,
});
return object; // already typed as Finding[]
}
Three things to notice:
- No parsing. No regex. No
try { JSON.parse(text) } catch. The SDK does it. - No casting.
objectis typed asFinding[], end of story. - No "did the model hallucinate a field?" anxiety. If the model returns something that doesn't match the schema, the SDK retries or throws. Either way, the bug never escapes into your business logic.
This is what I mean by agent contracts. The schema is a hard boundary between "untrusted LLM text" and "trusted typed data." Once you pass it, the model is just another component.
The same pattern works for the supervisor:
const ReviewReportSchema = z.object({
score: z.number().int().min(0).max(100),
summary: z.string(),
recommendation: z.string(),
findings: FindingArraySchema,
});
export async function runSupervisorAgent(findings: Finding[], meta: CodeMetadata) {
const { object } = await generateObject({
model: SUPERVISOR_MODEL, // claude-haiku-4.5
schema: ReviewReportSchema,
system: SUPERVISOR_PROMPT,
prompt: `Code metadata: ${meta.lang}, ${meta.lines} lines\n\nRaw findings:\n${JSON.stringify(findings, null, 2)}`,
});
return object;
}
Same idea, different schema. The supervisor's prompt is a few sentences telling it to deduplicate, prioritize by severity (security > performance > maintainability when severity ties), and assign a 0–100 score with cutoffs (90+ = production-ready, <50 = significant problems). The schema enforces that the score is an integer 0–100, the summary is a string, and the findings are still valid Finding[].
Decision 3 — Single SSE endpoint, no Redis
The most tempting bad architecture for "long-running multi-step jobs" is:
- Client
POST /jobs/start→ returns ajobId. - Client polls
GET /jobs/:id/statusevery second. - Server writes job state to Redis or KV between calls.
This adds a whole external dependency (Redis), introduces stale-state bugs, and gives the user a worse UX (1-second polling intervals look chunky).
The cleaner pattern: the POST request itself is the stream. The browser opens the connection, the server pushes events as the job progresses, and when the job is done the connection closes.
Server side:
export async function POST(req: Request) {
const body = await req.json();
const encoder = new TextEncoder();
const stream = new ReadableStream({
async start(controller) {
const send = (event: object) => {
controller.enqueue(encoder.encode(`data: ${JSON.stringify(event)}\n\n`));
};
try {
await orchestrate(send, body);
} catch (err) {
send({ type: 'error', message: String(err) });
} finally {
controller.close();
}
},
});
return new Response(stream, {
headers: {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
},
});
}
The send function is a simple closure that emits a Server-Sent Event. Inside orchestrate, every step calls send() when it starts, when it produces results, when it errors:
send({ type: 'started', jobId });
send({ type: 'step', name: 'parseInput', status: 'done' });
send({ type: 'agent', name: 'security', status: 'running' });
// ... agent runs in parallel ...
send({ type: 'agent', name: 'security', status: 'done', findings });
// ... supervisor runs ...
send({ type: 'report', report });
send({ type: 'done' });
Client side, the browser reads the stream:
const res = await fetch('/api/review', { method: 'POST', body: JSON.stringify({ ... }) });
const reader = res.body!.getReader();
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const events = buffer.split('\n\n');
buffer = events.pop() ?? '';
for (const event of events) {
if (!event.startsWith('data: ')) continue;
const parsed = JSON.parse(event.slice(6));
setEvents(prev => [...prev, parsed]);
}
}
That's it. No setInterval. No second endpoint. No Redis. The state lives in the streaming response, the job dies when the connection closes, and the client gets real-time updates with zero polling overhead.
The only constraint: this works inside a single function invocation. If your job is too slow for the platform's max function duration, you do need a real job queue. But for "three agents + a supervisor in 30 seconds total," it's perfect.
Why Haiku for the supervisor
A small but cost-relevant choice: I use Sonnet for the three specialists and Haiku for the supervisor.
The specialists are doing real reasoning: parsing code, identifying vulnerabilities, suggesting fixes with diffs. They benefit from Sonnet's depth.
The supervisor is doing mechanical work: sort, deduplicate, prioritize, summarize, score. None of those require deep reasoning about the code itself — the supervisor never sees the code, only the structured findings. Haiku is plenty.
Concretely:
- A typical review fires 4 LLM calls (3 specialists + 1 supervisor).
- Three of those are Sonnet, one is Haiku — significantly cheaper than four Sonnet calls, and indistinguishable in output quality for the supervisor's specific job.
This is a generalizable lesson: the model you pick should match the cognitive complexity of the task, not the impressiveness of the system overall. A multi-agent system with a Haiku-powered supervisor is still a sophisticated system. You don't gain anything by paying Sonnet rates for a task Haiku does fine.
What I learned
Three things I'll carry forward:
- Specialists + supervisor beats one big agent. Splitting a fuzzy task into focused sub-tasks gives the model less cognitive overhead per call and produces more balanced output. The mental model is closer to a human team than a brain-in-a-vat.
- Zod schemas are non-negotiable for LLM tool outputs. Treat the schema as the contract. Your business logic should never see free-form model text — only validated typed data.
- Streams beat polling for any job that takes 5–60 seconds. SSE inside a single POST is the cleanest pattern I've found. Use it as the default; reach for a real job queue only when you actually exceed function duration.
The full code, including the code-input editor, the workflow-progress timeline component, and all four agent prompts, is on GitHub. Live demo accepts both pasted snippets and GitHub file URLs.
🔗 github.com/NeryC/multi-agent-code-reviewer
🔗 Live demo: multi-agent-code-reviewer-sable.vercel.app